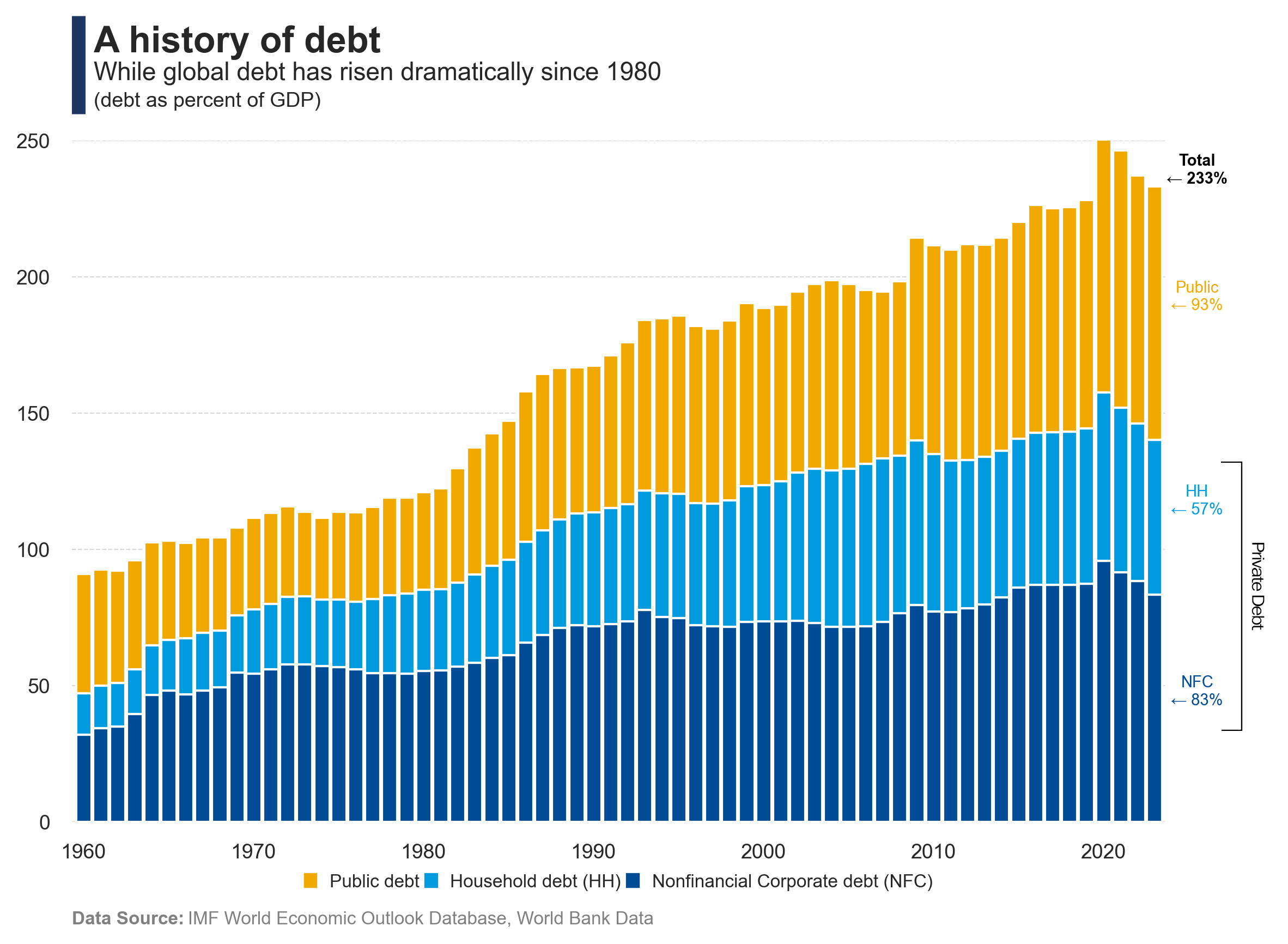
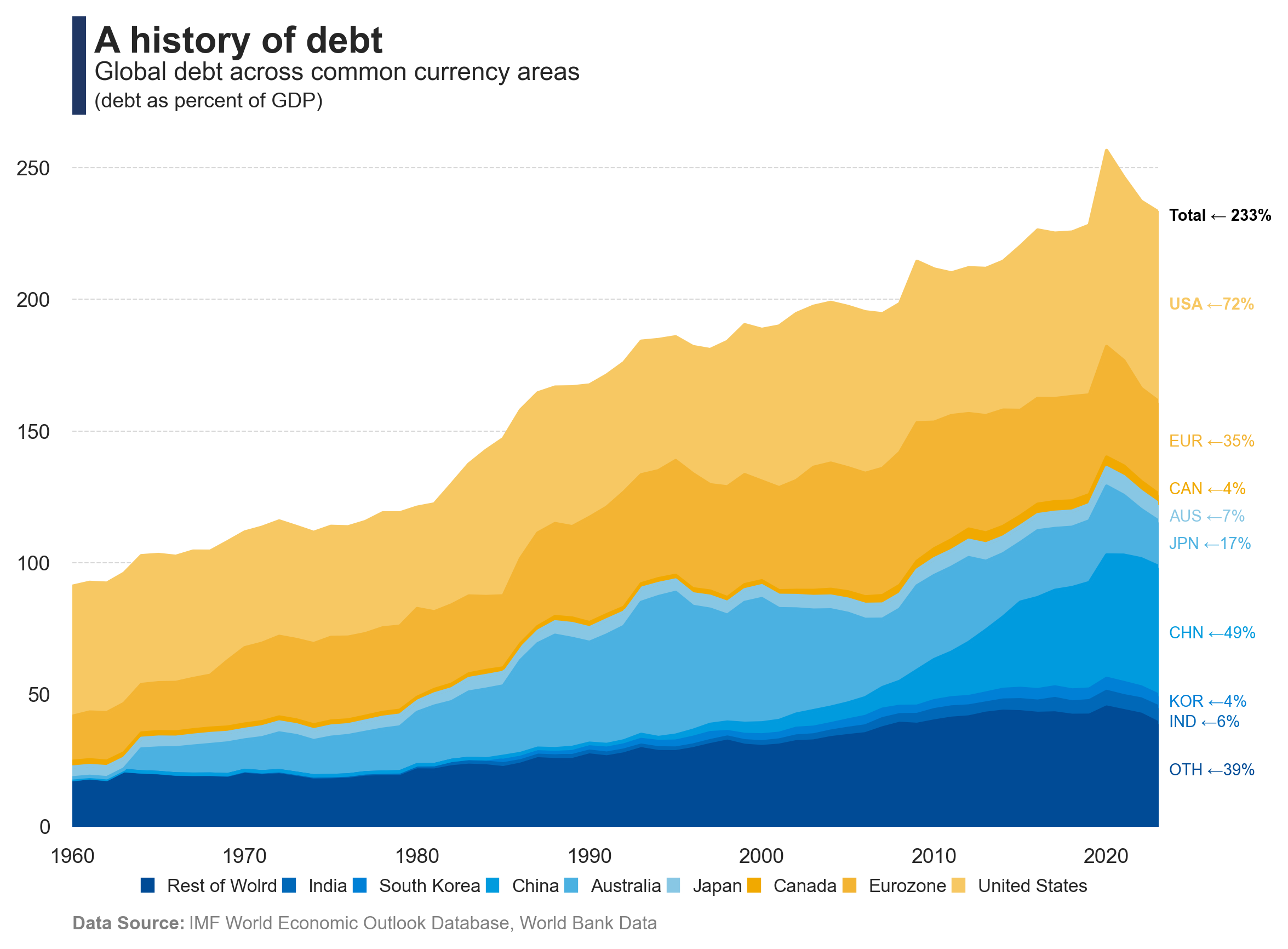
Exploring the evolution of global debt and its structure.
Published
May 18, 2026
Keywords
global debt
Summary
The chart shows the evolution of global debt over time, highlighting its structural composition. It provides insights into how debt levels have changed reached record levels during last years.
Code
# Libraries# =====================================================================import requestsimport wbgapi as wbimport pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltimport matplotlib.patches as mpatchesimport matplotlib.ticker as tickerimport matplotlib.ticker as mtickerimport os# Data Extraction (Countries)# =====================================================================# Extract JSON and bring data to a dataframeurl ='https://raw.githubusercontent.com/guillemmaya92/world_map/main/Dim_Country.json'response = requests.get(url)data = response.json()df = pd.DataFrame(data)df = pd.DataFrame.from_dict(data, orient='index').reset_index()df_countries = df.rename(columns={'index': 'ISO3'})# Data Extraction - WBD (1960-1980)# ========================================================# To use the built-in plotting methodindicator = ['NY.GDP.PCAP.KD', 'SP.POP.TOTL']countries = df_countries['ISO3'].tolist()data_range =range(1960, 1980)data = wb.data.DataFrame(indicator, countries, data_range, numericTimeKeys=True, labels=False, columns='series').reset_index()df_wb = data.rename(columns={'economy': 'ISO3','time': 'Year','SP.POP.TOTL': 'pop','NY.GDP.PCAP.KD': 'gdpc'})# Filter nulls and create totaldf_wb = df_wb[~df_wb['gdpc'].isna()]df_wb['Value'] = df_wb['gdpc'] * df_wb['pop']df_wb['Parameter'] ='NGDPD'df_wb = df_wb[['Parameter', 'ISO3', 'Year', 'Value']]# Data Extraction (IMF)# =====================================================================#Parametroparameters = ['NGDPD', 'PVD_LS', 'HH_LS', 'NFC_LS', 'CG_DEBT_GDP', 'GG_DEBT_GDP', 'NFPS_DEBT_GDP', 'PS_DEBT_GDP']# Create an empty listrecords = []# Iterar sobre cada parámetrofor parameter in parameters:# Request URL url =f"https://www.imf.org/external/datamapper/api/v1/{parameter}" response = requests.get(url) data = response.json() values = data.get('values', {})# Iterate over each country and yearfor country, years in values.get(parameter, {}).items():for year, value in years.items(): records.append({'Parameter': parameter,'ISO3': country,'Year': int(year),'Value': float(value) })# Create dataframedf_imf = pd.DataFrame(records)# Data Manipulation# =====================================================================# Merge IMF and WBDdf = pd.concat([df_imf, df_wb], ignore_index=True)# Pivot Parameter to columns and filter nullsdf = df.pivot(index=['ISO3', 'Year'], columns='Parameter', values='Value').reset_index()df = df.dropna(subset=['PVD_LS', 'HH_LS', 'NFC_LS', 'CG_DEBT_GDP', 'GG_DEBT_GDP', 'NFPS_DEBT_GDP', 'PS_DEBT_GDP'], how='all')# Calculate Totalsdf['GDP'] = df['NGDPD']df['Public'] = df['GG_DEBT_GDP'].fillna(df['CG_DEBT_GDP']).fillna(df['NFPS_DEBT_GDP']) * df['GDP']df['HH'] = df['HH_LS'] * df['GDP']df['NFC'] = df['NFC_LS'].fillna(df['PVD_LS']) * df['GDP']# Merge countriesdf = df.merge(df_countries, how='left', left_on='ISO3', right_on='ISO3')df = df[['ISO3', 'Country', 'Year', 'GDP', 'NFC', 'HH', 'Public']]df = df[df['Country'].notna()]# Groupping datadf = df.groupby('Year', as_index=False)[['GDP', 'NFC', 'HH', 'Public']].sum()# Percentdf['NFC'] = df['NFC'] / df['GDP']df['HH'] = df['HH'] / df['GDP']df['Public'] = df['Public'] / df['GDP']# Adjust tabledf.drop(columns=['GDP'], inplace=True)df = df[df['Year'] >=1960]df.set_index('Year', inplace=True)print(df)# Data Visualization# =====================================================================# Font and styleplt.rcParams.update({'font.family': 'sans-serif', 'font.sans-serif': ['Franklin Gothic'], 'font.size': 9})sns.set(style="white", palette="muted")# Palettepalette = ["#004b96", "#009bde", "#f1a900"]# Create figurefig, ax = plt.subplots(figsize=(8, 6))# Crear figure and plotdf.plot(kind="bar", stacked=True, width=0.9, color=palette, legend=False, ax=ax)# Add title and labelsfig.add_artist(plt.Line2D([0.07, 0.07], [0.87, 0.97], linewidth=6, color='#203764', solid_capstyle='butt'))plt.text(0.02, 1.13, f'A history of debt', fontsize=16, fontweight='bold', ha='left', transform=plt.gca().transAxes)plt.text(0.02, 1.09, f'While global debt has risen dramatically since 1980', fontsize=11, color='#262626', ha='left', transform=plt.gca().transAxes)plt.text(0.02, 1.05, f'(debt as percent of GDP)', fontsize=9, color='#262626', ha='left', transform=plt.gca().transAxes)# Adjust ticks and gridplt.ylim(0, 250)ax.yaxis.set_major_formatter(mticker.FuncFormatter(lambda x, pos: f'{int(x):,}'.replace(",", ".")))ax.xaxis.set_major_locator(ticker.MultipleLocator(10))plt.gca().set_xlabel('')plt.yticks(fontsize=9, color='#282828')plt.xticks(fontsize=9, rotation=0)plt.grid(axis='y', linestyle='--', color='gray', linewidth=0.5, alpha=0.3)# Custom legend valueshandles = [ mpatches.Patch(color=palette[2], label="Public debt", linewidth=2), mpatches.Patch(color=palette[1], label="Household debt (HH)", linewidth=2), mpatches.Patch(color=palette[0], label="Nonfinancial Corporate debt (NFC)", linewidth=2)]# Legendplt.legend( handles=handles, loc='lower center', bbox_to_anchor=(0.5, -0.12), ncol=4, fontsize=8, frameon=False, handlelength=0.5, handleheight=0.5, borderpad=0.2, columnspacing=0.4)# Add Data Sourceplt.text(0, -0.15, 'Data Source:', transform=plt.gca().transAxes, fontsize=8, fontweight='bold', color='gray')space =" "*23plt.text(0, -0.15, space +'IMF World Economic Outlook Database, World Bank Data', transform=plt.gca().transAxes, fontsize=8, color='gray')# Remove spinesfor spine in plt.gca().spines.values(): spine.set_visible(False)# Add textpublic = df.loc[2023, 'Public']household = df.loc[2023, 'HH']nonfinancial = df.loc[2023, 'NFC']plt.text(len(df)+1.5, nonfinancial/2, f"NFC\n← {nonfinancial:.0f}%", fontsize=7, ha='center', va='bottom', color='#004b96')plt.text(len(df)+1.5, nonfinancial + (household/2), f"HH\n← {household:.0f}%", fontsize=7, ha='center', va='bottom', color='#009bde')plt.text(len(df)+1.5, nonfinancial + household + (public/2), f"Public\n← {public:.0f}%", fontsize=7, ha='center', va='bottom', color='#f1a900')plt.text(len(df)+1.5, nonfinancial + household + public, f"Total\n← {nonfinancial+household+public:.0f}%", fontsize=7, ha='center', va='bottom', fontweight='bold', color='black')# Añadir el texto estiradoplt.text(len(df)+5, (nonfinancial + household) /2, "}", fontsize=40, ha='center', va='bottom', color='#ffffff')# Adjust layoutplt.tight_layout()# Save it...download_folder = os.path.join(os.path.expanduser("~"), "Downloads")filename = os.path.join(download_folder, f"FIG_IMF_Global_Debt.png")plt.savefig(filename, dpi=300, bbox_inches='tight')# Show :)plt.show()