Examining Social and Economic Inequalities Amid China’s Urbanization
Published
Jun 12, 2026
Keywords
urbanization
Summary
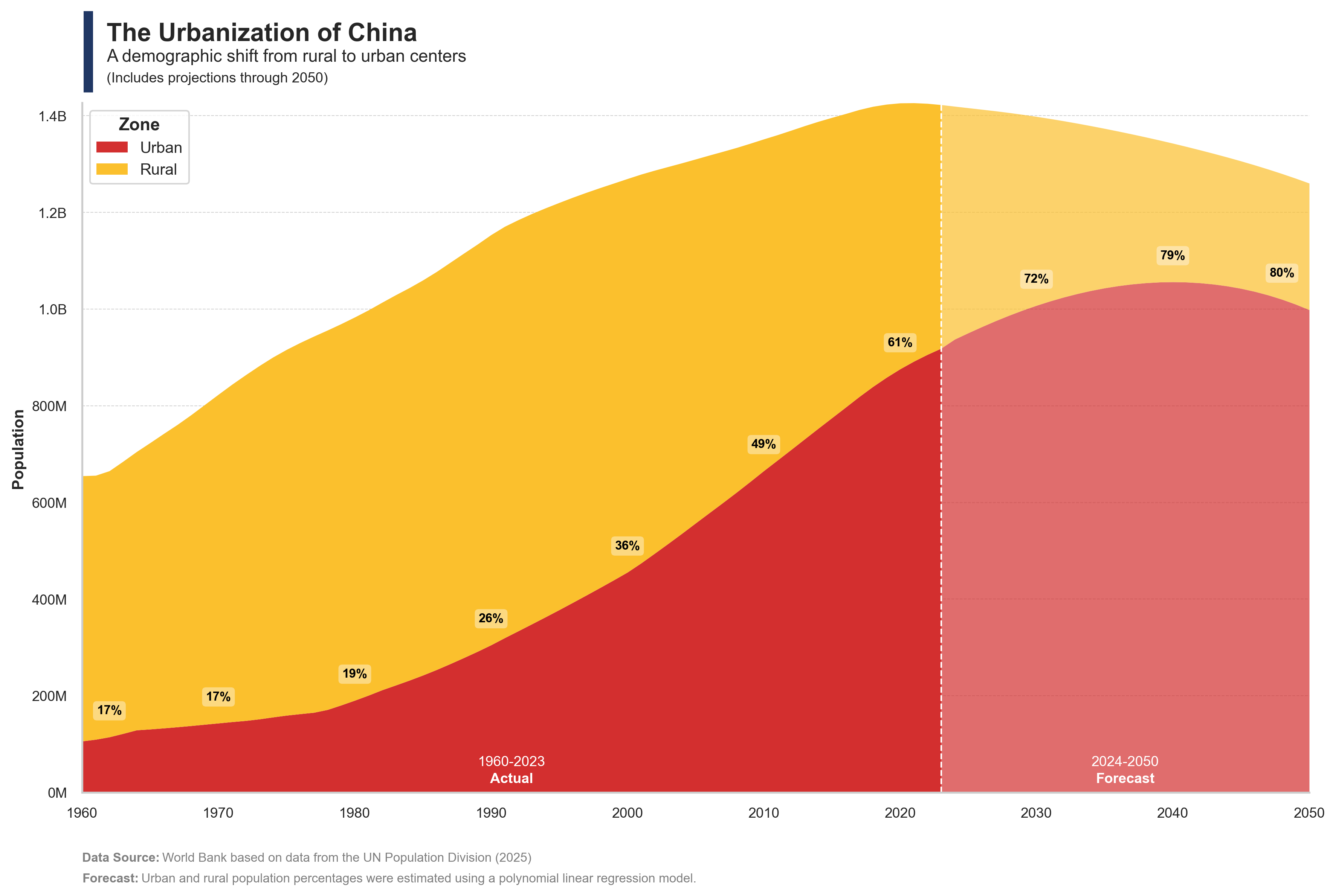
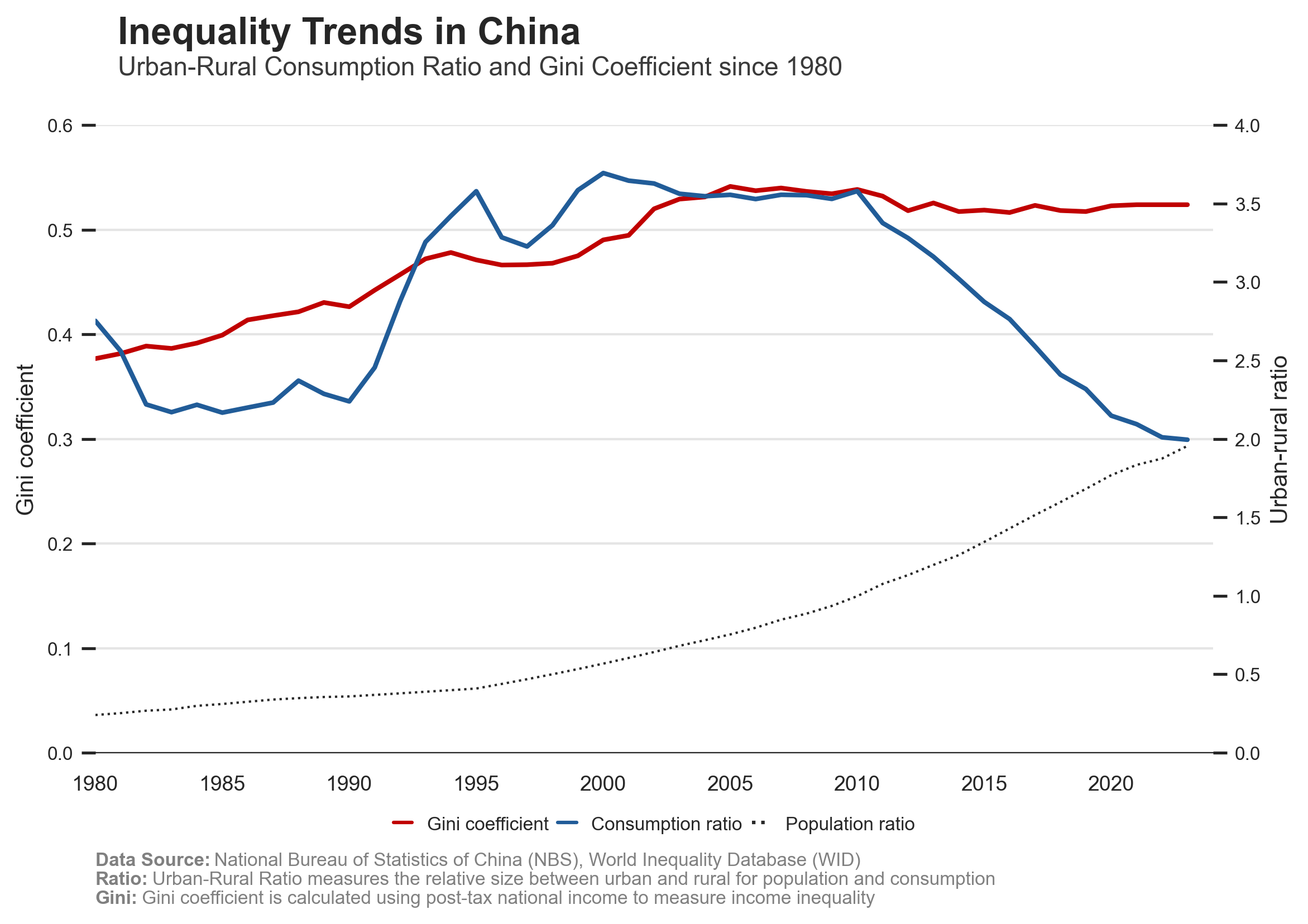
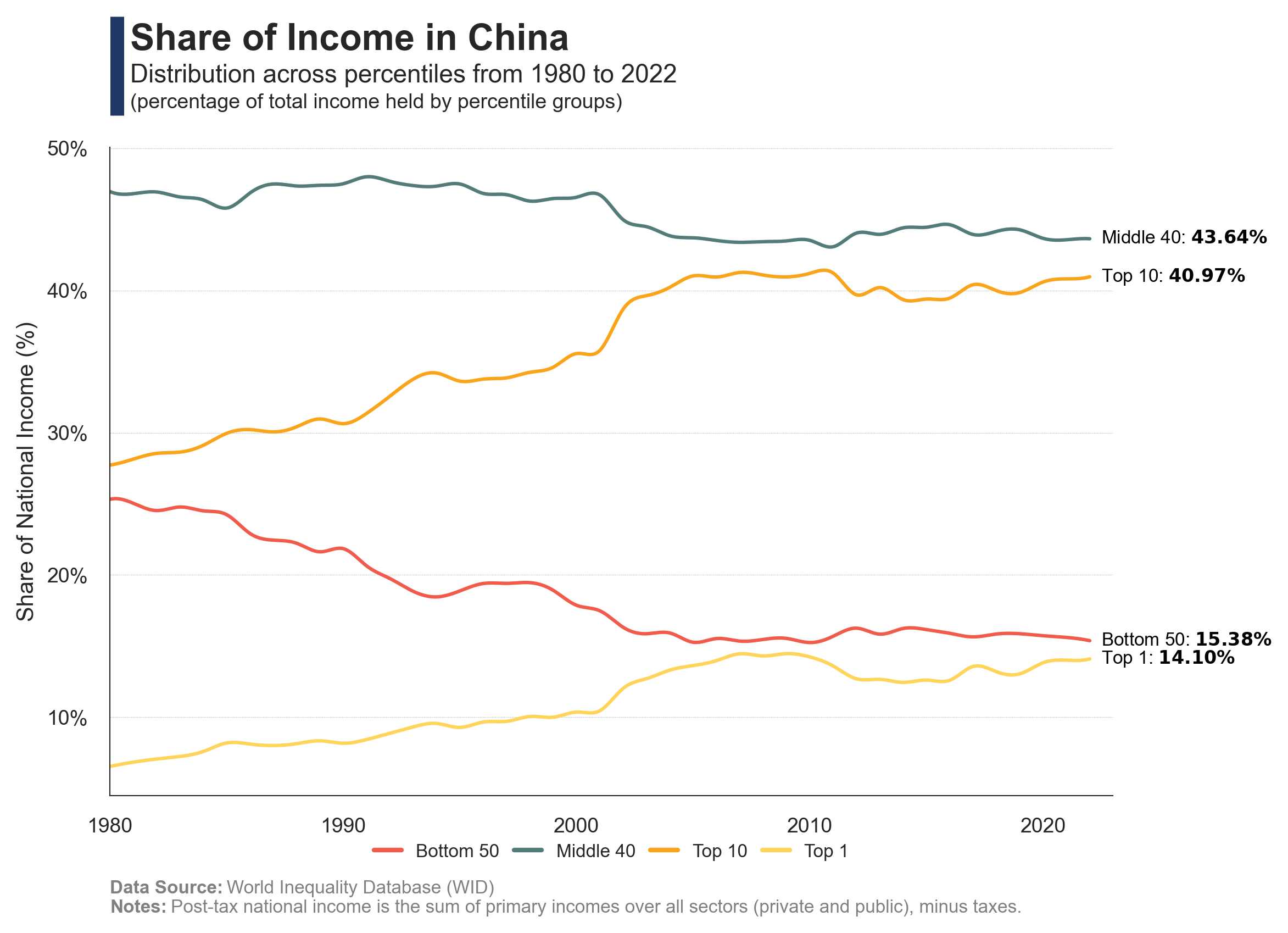
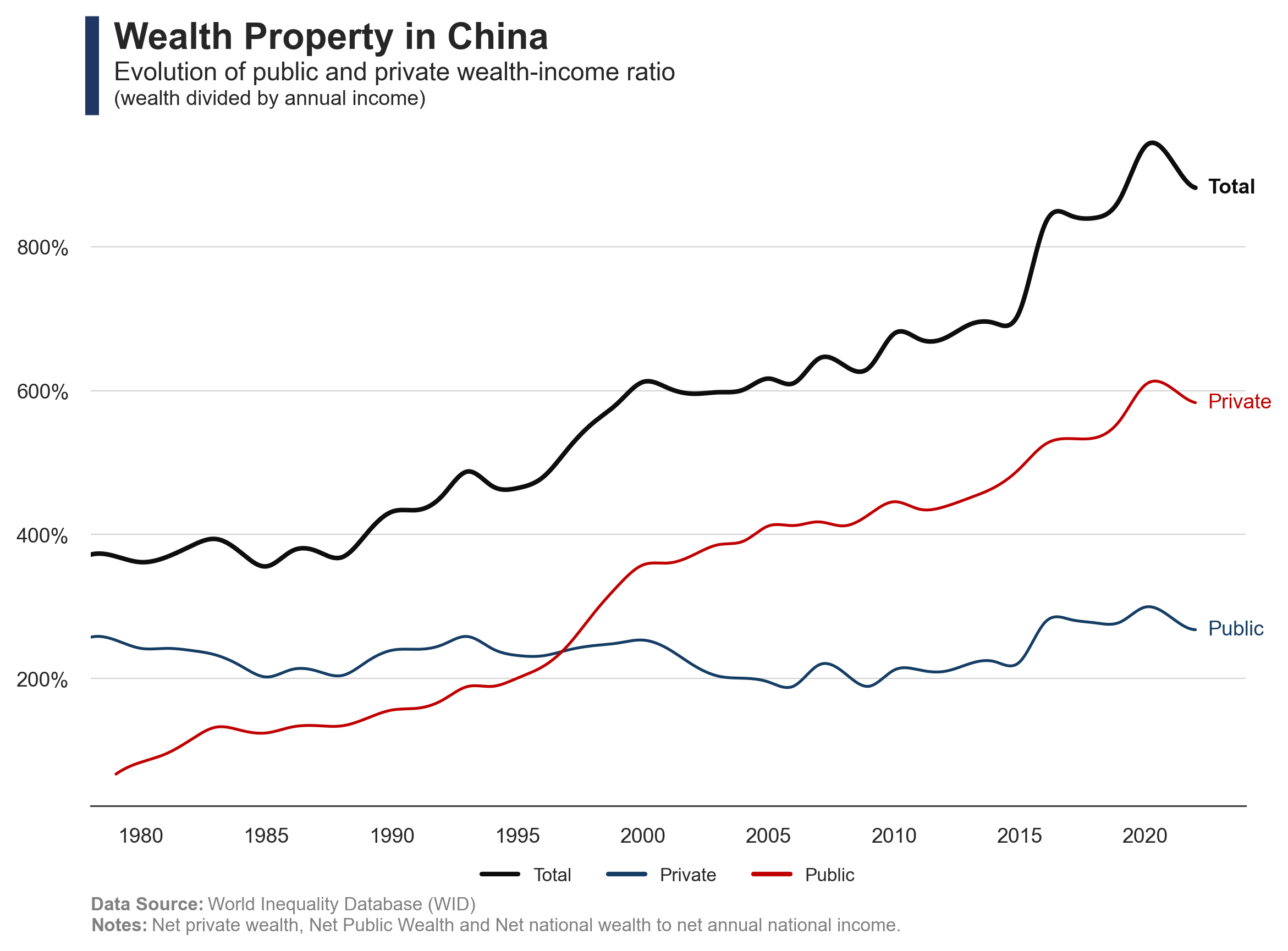
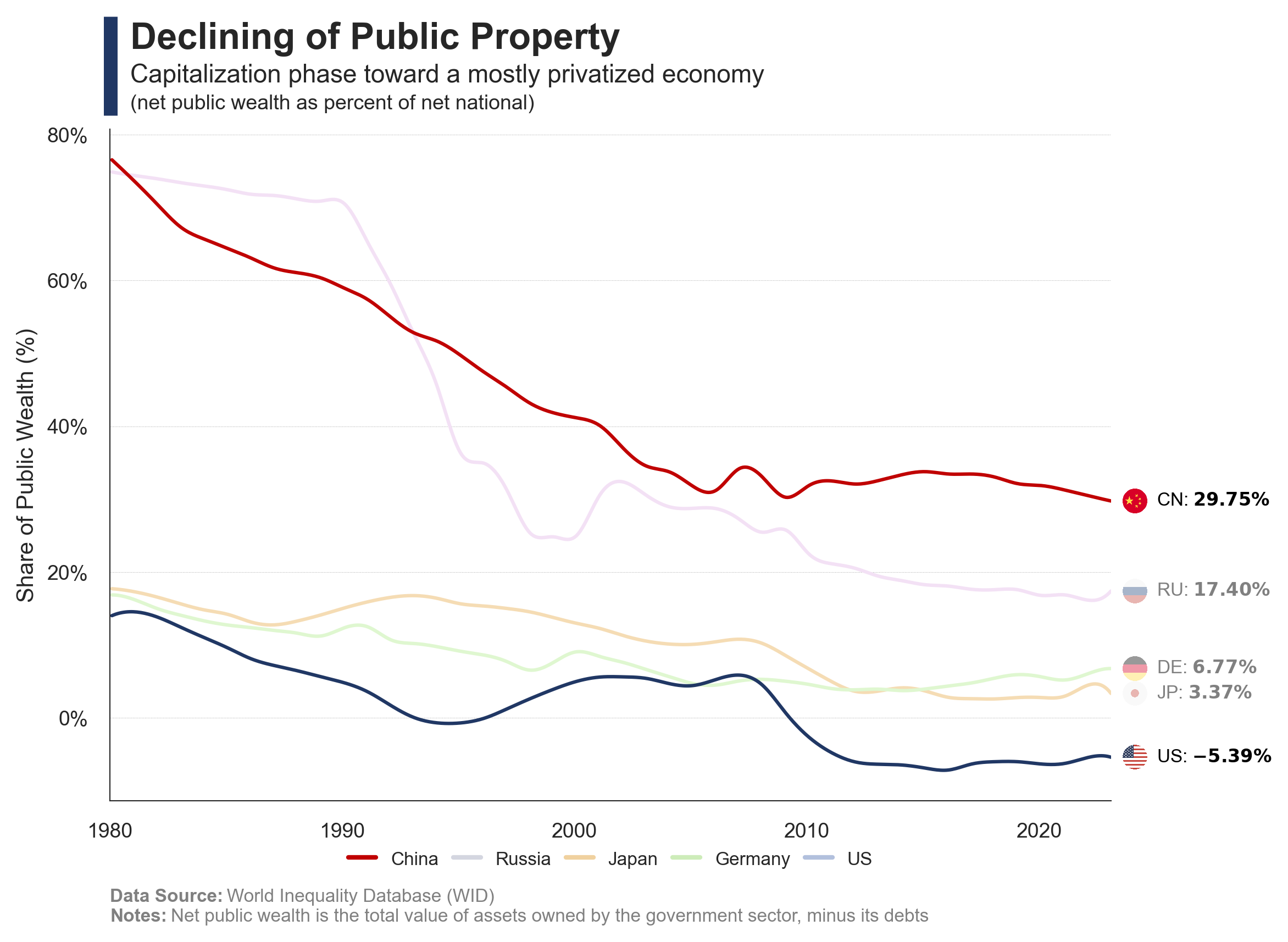
The charts illustrate the evolution of urbanization in China, the income inequality between rural and urban populations, and the scale of income distribution across cities.
Code
# Libraries# ========================================================import pandas as pdimport numpy as npimport osfrom sklearn.linear_model import LinearRegressionfrom sklearn.preprocessing import PolynomialFeaturesimport matplotlib.pyplot as pltimport seaborn as snsimport matplotlib.font_manager as fm# Parameters# ========================================================code_iso ='CHN'name_iso ='China'max_urban =0.82year_pred =1980# Data Extraction (urban and rural)# ========================================================# OWD Urban and Rural Population Datadf = pd.read_csv("https://ourworldindata.org/grapher/share-of-population-urban.csv?v=1&csvType=full&useColumnShortNames=true", storage_options = {'User-Agent': 'Our World In Data data fetch/1.0'})df = df[df['Code'] == code_iso]df = df[(df['Year'] >=1960) & (df['Year'] <=2023)]df['Urban'] = df['sp_urb_totl_in_zs'] /100df = df[['Code', 'Year', 'Urban']]# Variablesdfx = df[df['Year'] >= year_pred]X = dfx[['Year']]y = dfx['Urban']# Transformar to polynomialpoly = PolynomialFeatures(degree=3)X_poly = poly.fit_transform(X)# Training modelmodel = LinearRegression()model.fit(X_poly, y)# Future year rangefuture_years = pd.DataFrame({'Year': range(2024, 2051)})future_X_poly = poly.transform(future_years)# Predictionfuture_preds = model.predict(future_X_poly)# Limit prediction to max_urbanfuture_preds = np.clip(future_preds, None, max_urban)# Dataframe predictionfuture_df = pd.DataFrame({'Code': code_iso,'Year': future_years['Year'],'Urban': future_preds})# Concatenate future predictions with original dataframedf = pd.concat([df, future_df], ignore_index=True)# Add rural percentagedf['Rural'] =1- df['Urban']# Data Extraction (population)# ========================================================# OWD Population Datadfp = pd.read_csv("https://ourworldindata.org/grapher/population-long-run-with-projections.csv?v=1&csvType=full&useColumnShortNames=true", storage_options = {'User-Agent': 'Our World In Data data fetch/1.0'})dfp = dfp[dfp['Code'] == code_iso]dfp = dfp[dfp['Year'] >=1960]dfp['Total'] = dfp['population_projection'].fillna(0) + dfp['population_historical'].fillna(0)dfp = dfp[['Code', 'Year', 'Total']]# Merge urban and rural data with population datadf = df.merge(dfp, on=['Code', 'Year'], how='left')df['Urban_Per'] = df['Urban']df['Urban'] = df['Urban'] * df['Total']df['Rural'] = df['Rural'] * df['Total']df = df[['Code', 'Year', 'Urban', 'Rural', 'Urban_Per']]print(df)# Data Visualization# ========================================================# Seaborn figure stylesns.set(style="whitegrid")fig, ax = plt.subplots(figsize=(12, 8))# Create a palettepalette1 = ["#D32F2F", "#FBC02D"] # 1960–2023# Separar periods (actual and forecast)df1 = df[df['Year'] <=2023].copy()df2 = df[df['Year'] >=2023].copy()# Create stacked area plotdf1.set_index('Year')[['Urban', 'Rural']].plot( kind="area", stacked=True, color=palette1, ax=ax, linewidth=0)df2.set_index('Year')[['Urban', 'Rural']].plot( kind="area", stacked=True, color=palette1, ax=ax, linewidth=0, alpha=0.7, legend=False)# Titlefig.add_artist(plt.Line2D([0.073, 0.073], [0.90, 0.99], linewidth=6, color='#203764', solid_capstyle='butt'))ax.text(0.02, 1.09, f'The Urbanization of {name_iso}', fontsize=16, fontweight='bold', ha='left', transform=plt.gca().transAxes)ax.text(0.02, 1.06, f'A demographic shift from rural to urban centers', fontsize=11, color='#262626', ha='left', transform=plt.gca().transAxes)ax.text(0.02, 1.03, f'(Includes projections through 2050)', fontsize=9, color='#262626', ha='left', transform=plt.gca().transAxes)# Configurationax.set_xlim(1960, 2050)ax.set_xlabel('')ax.set_ylabel('Population', fontsize=10, fontweight='bold')ax.grid(axis='x')ax.grid(axis='y', linestyle='--', linewidth=0.5, color='lightgray')ax.tick_params(axis='x', labelsize=9)ax.tick_params(axis='y', labelsize=9) ax.yaxis.set_major_formatter(plt.FuncFormatter(lambda x, _: f'{x/1e9:.1f}B'if x >=1e9elsef'{x/1e6:.0f}M'))ax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)max_total = (df["Urban"] + df["Rural"]).max()# Establecer el límite del eje yax.set_ylim(top=max_total)# White vertical line at 2023ax.axvline(x=2023, color='white', linestyle='--', linewidth=1)# Add text labels for urban percentagesy_offset = df['Urban'].max() *0.04for i, year inenumerate(df['Year']):if year %10==0and year notin [1960, 2050] or year in [1962, 2048]: urban_value = df.loc[i, 'Urban'] urban_per = df.loc[i, 'Urban_Per'] ax.text( year, urban_value + y_offset,f'{urban_per:.0%}', ha='center', va='bottom', fontsize=8, color='black', weight='bold', bbox=dict(facecolor='white', alpha=0.4, edgecolor='none', boxstyle='round,pad=0.3') )# Legend configurationhandles, labels = ax.get_legend_handles_labels()title_font = fm.FontProperties(weight='bold', size=11)ax.legend( handles[:2], labels[:2], title="Zone", title_fontproperties=title_font, fontsize=10, loc='upper left')# Actual texty_max = ax.get_ylim()[1]plt.text( x=(2023-1960)/2+1960, y=y_max*0.035, s="1960-2023", fontsize=9, color='white', ha='center', va='bottom')plt.text( x=(2023-1960)/2+1960, y=y_max*0.01, s="Actual", fontsize=9, fontweight='bold', color='white', ha='center', va='bottom')# Forecast textplt.text( x=(2050-2023)/2+2023, y=y_max*0.035, s="2024-2050", fontsize=9, color='white', ha='center', va='bottom')plt.text( x=(2050-2023)/2+2023, y=y_max*0.01, s="Forecast", fontsize=9, fontweight='bold', color='white', ha='center', va='bottom')# Add Data Sourceplt.text(0, -0.1, 'Data Source:', transform=plt.gca().transAxes, fontsize=8, fontweight='bold', color='gray')space =" "*23plt.text(0, -0.1, space +'World Bank based on data from the UN Population Division (2025)', transform=plt.gca().transAxes, fontsize=8, color='gray')# Add Notesplt.text(0, -0.12, 'Forecast:', transform=plt.gca().transAxes, fontsize=8, fontweight='bold', color='gray')space =" "*17plt.text(0, -0.12, space +'Urban and rural population percentages were estimated using a polynomial linear regression model.', transform=plt.gca().transAxes, fontsize=8, color='gray')# Adjust layoutplt.tight_layout()# Save it...download_folder = os.path.join(os.path.expanduser("~"), "Downloads")filename = os.path.join(download_folder, f"FIG_OWD_Population_Rural_Urban_{code_iso}.png")plt.savefig(filename, dpi=300, bbox_inches='tight')# Show :)plt.show()
Code
# Libraries# =====================================================================import pandas as pdimport numpy as npimport seaborn as snsimport matplotlib.pyplot as pltimport matplotlib.ticker as tickerimport requestsimport os# Data (China) # =====================================================================# Read wikipedia dataurl ="https://en.wikipedia.org/wiki/List_of_prefecture-level_divisions_of_China_by_GDP"headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36"}html = requests.get(url, headers=headers).texttables = pd.read_html(html)df = tables[0]df.columns = ['region', '1', '2', '3', 'gdp', '4', 'gdpc', '5']df['population'] = df['gdp'] / df['gdpc'] *1000df = df[['region', 'gdpc', 'population']]df['region'] = df['region'].str.replace('*', '', regex=False)data = pd.DataFrame({'region': ['Beijing', 'Shangai', 'Chongqing', 'Tianjin', 'Hong Kong', 'Macao', 'Taiwan'],'gdpc': [28294, 26747, 12350, 17727, 48800, 36909, 32756],'population': [21.8, 24.7, 32.0, 13.9, 7.5, 0.68, 23.3],})df = pd.concat([df, data], ignore_index=True)# Data Manipulation# =====================================================================# Order dataframedf = df.sort_values(by=['gdpc'])# Calculate 'left accrual widths'df['population_cum'] = df['population'].cumsum()df['left'] = df['population'].cumsum() - df['population']# Pondered Gini Functiondef gini(x, weights=None):if weights isNone: weights = np.ones_like(x) count = np.multiply.outer(weights, weights) mad = np.abs(np.subtract.outer(x, x) * count).sum() / count.sum() rmad = mad / np.average(x, weights=weights)return0.5* rmad# Calculate gini and mediangini_index = gini(df['gdpc'].values, df['population'].values)# Calculate weighted mediandf.sort_values('gdpc', inplace=True)cumsum = df['population'].cumsum()cutoff = df['population'].sum() /2.0median = df.loc[cumsum >= cutoff, 'gdpc'].iloc[0]# Show dataframe, gini and medianprint(df)print(gini_index)print(median)# Data Visualization# =====================================================================# Seaborn figure stylesns.set(style="whitegrid")fig, ax = plt.subplots(figsize=(12, 8))# Create a palettenorm = plt.Normalize(df["gdpc"].min(), 25000)colors = plt.cm.coolwarm_r(norm(df["gdpc"]))# Create a Matplotlib plotbars = plt.bar(df['left'], df['gdpc'], width=df['population'], color=colors, alpha=1, align='edge', edgecolor='grey', linewidth=0.1)# Titlefig.add_artist(plt.Line2D([0.085, 0.085], [0.90, 0.985], linewidth=6, color='#203764', solid_capstyle='butt'))ax.text(0.02, 1.09, f'Regional GDP Distribution of China', fontsize=16, fontweight='bold', ha='left', transform=plt.gca().transAxes)ax.text(0.02, 1.06, f'From rural to urban, the role of location in income inequality', fontsize=11, color='#262626', ha='left', transform=plt.gca().transAxes)ax.text(0.02, 1.03, f'(GDP per capita in $US)', fontsize=9, color='#262626', ha='left', transform=plt.gca().transAxes)# Configuration grid and labelsax.set_xlim(0, df['population_cum'].max()) ax.set_ylim(0, df['gdpc'].max() *1.093)ax.set_xlabel('Cumulative Population (M)', fontsize=10, fontweight='bold')ax.set_ylabel('GDP per capita ($USD)', fontsize=10, fontweight='bold')ax.grid(axis='x')ax.grid(axis='y', linestyle='--', linewidth=0.5, color='lightgray')ax.tick_params(axis='x', labelsize=9)ax.tick_params(axis='y', labelsize=9) ax.yaxis.set_major_formatter(ticker.FuncFormatter(lambda x, _: f'{int(x):,}'))ax.xaxis.set_major_formatter(ticker.FuncFormatter(lambda x, _: f'{int(x):,}'))ax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)ax.axhline(y=median, color='red', linestyle='--', linewidth=0.5, zorder=0, alpha=0.4)ax.text(75, median +100, f"Median: {median:,.0f}$", color='darkred', fontweight='bold', fontsize=9, ha='center', va='bottom', zorder=2)# Add text each region except Ávila and Segoviafor i, bar inenumerate(bars): region_name = df['region'].iloc[i] top_cities = ['Beijing', 'Shangai', 'Chongqing', 'Tianjin', 'Hong Kong','Ordos', 'Suzhou, Jiangsu', 'Zhenjiang', 'Jieyang', 'Kashgar', 'Shangrao', 'Qujing','Shenzhen', 'Guangzhou', 'Suzhou', 'Chengdu', 'Wuhan', 'Hangzhou', 'Nanjing','Ningbo', 'Qingdao', 'Wuxi', 'Changsha', 'Zhengzhou', 'Fuzhou', 'Quanzhou','Jinan', 'Dongguan', 'Foshan', "Xi'an", 'Dalian', 'Wenzhou', 'Shenyang','Kunming', 'Baoding', 'Shijiazhuang', 'Linyi', 'Harbin', 'Nanyang','Weifang', 'Handan', 'Changchun', 'Xuzhou', 'Ganzhou', 'Zhoukou', 'Nanning','Heze', 'Fujian', 'Jining', 'Shaoyang', 'Hefei', 'Nantong', 'Shangqiu','Tangshan', 'Hengyang', 'Cangzhou', 'Jinhua', 'Luoyang', 'Xingtai','Zhanjiang', 'Zhumadian', 'Bijie', 'Taiwan', 'Macao' ]# Add labelsif region_name in top_cities: x = bar.get_x() + bar.get_width() /2 y = bar.get_height()# Special positionif region_name =="Macao": x +=-8 y +=1000elif region_name =="Ordos": x +=-2 y +=3500elif region_name in ["Jinan", "Foshan", "Qingdao"]: x -=5 y +=1000else: y +=1000 ax.text( x, y, region_name, ha='center', va='bottom', color='#363636', fontsize=7, rotation=90, )# Add Year label ax.text(1, 1.12, f'2022', transform=plt.gca().transAxes, fontsize=22, ha='right', va='top', fontweight='bold', color='#D3D3D3')# Add Data Sourceax.text(0, -0.1, 'Data Source: National Bureau of Statistics of China', transform=plt.gca().transAxes, fontsize=8, color='gray')# Show GINI Indexax.text(0.09, 0.97, f"Gini Index: {gini_index:.2f}", transform=ax.transAxes, fontsize=8.5, color='black', ha='right', va='top', bbox=dict(boxstyle="round,pad=0.3", edgecolor='gray', facecolor='white'))# Add Gini Indexax.text(0, -0.12, 'Notes: The Gini coefficient has been calculated using population weights for each region.', transform=plt.gca().transAxes, fontsize=8, color='gray')# Add label "poorest" and "richest"ax.text(0, -0.065, 'Low Income', transform=ax.transAxes, fontsize=11, fontweight='bold', color='darkred', ha='left', va='center')ax.text(0.915, -0.065, 'High Income', transform=ax.transAxes, fontsize=11, fontweight='bold', color='darkblue', va='center')# Adjust layoutplt.tight_layout()# Save it...download_folder = os.path.join(os.path.expanduser("~"), "Downloads")filename = os.path.join(download_folder, f"FIG_BUREAU_Region_Distribution_China_Prefecture.png")plt.savefig(filename, dpi=300, bbox_inches='tight')# Show :)plt.show()